Scaling Categorical Flow Maps
Abstract Hide abstract
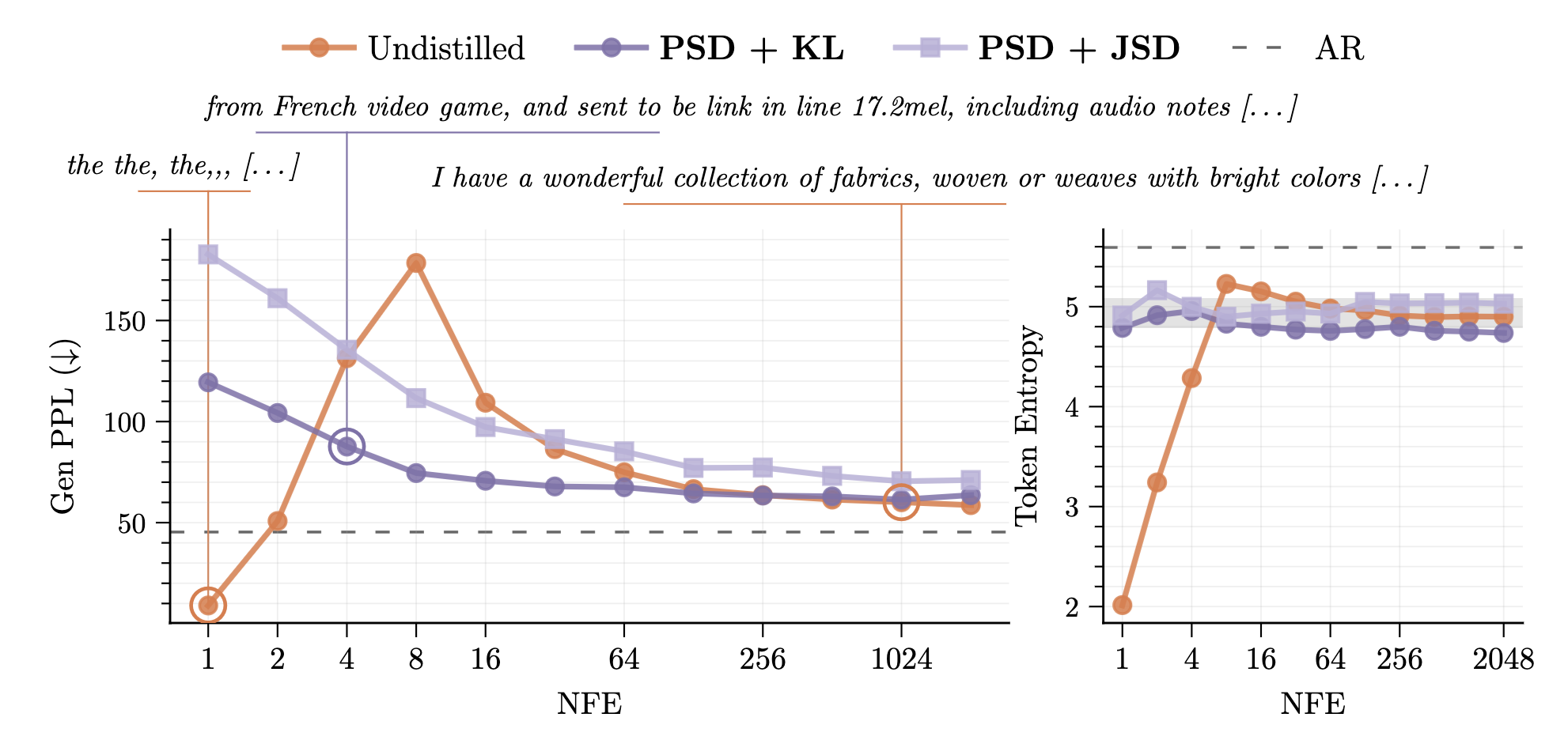
Continuous diffusion and flow matching models could represent a powerful alternative to autoregressive approaches for language modelling (LM), as they unlock a host of advantages currently reserved for continuous modalities, including accelerated sampling and tilting. Recently, several works have demonstrated the possibility of generating discrete data continuously by a simple flow matching process between a Gaussian and the one-hot encoded data distribution. They have further shown the feasibility of accelerated sampling via Categorical Flow Maps (CFMs), resulting in competitive sample quality in the few-step regime. However, this method had only been evaluated at relatively modest scales (<1B), leaving the question of its scalability completely open. In this article, we train a 1.7B-parameter base flow model on 2.1T tokens and self-distill it into a CFM that generates diverse, high-quality text in as few as 4 inference steps while maintaining near-data-level token entropy. Furthermore, we introduce a likelihood bound for CFMs in the semi-discrete setting, and show that they can be used to score the model on standard LM benchmarks, achieving results in the same range as discrete diffusion methods. Finally, we uncover some of the challenges that arise from training these models at scale, and we provide prescriptive insights on loss weighting and time scheduling.