My work primarily focuses on generative modelling. In particular, I am most interested in:
Diffusion & flow matching;
Accelerated methods (e.g., flow maps), and controlled generation;
Continuous processes for language generation (Categorical Flow Maps).
Education & Experience
I hold a BSc in Computer Science from EPFL with an exchange year at Imperial College London, and an MSc in Advanced Computer Science from the University of Oxford. I was also awarded the Tony Hoare Prize for the best MSc thesis of the year, Information Theoretic Perspectives on Graph Neural Networks.
Currently, I am interning at Apple MLR. I have previously worked at Microsoft Research, and Genesis Molecular AI.
My PhD funding is generously provided by both Project CETI and Intel.
Davis, O., Filippova, A., Ablin, P., Turrisi, V., Shidani, A., Cuturi, M., Béthune, L.
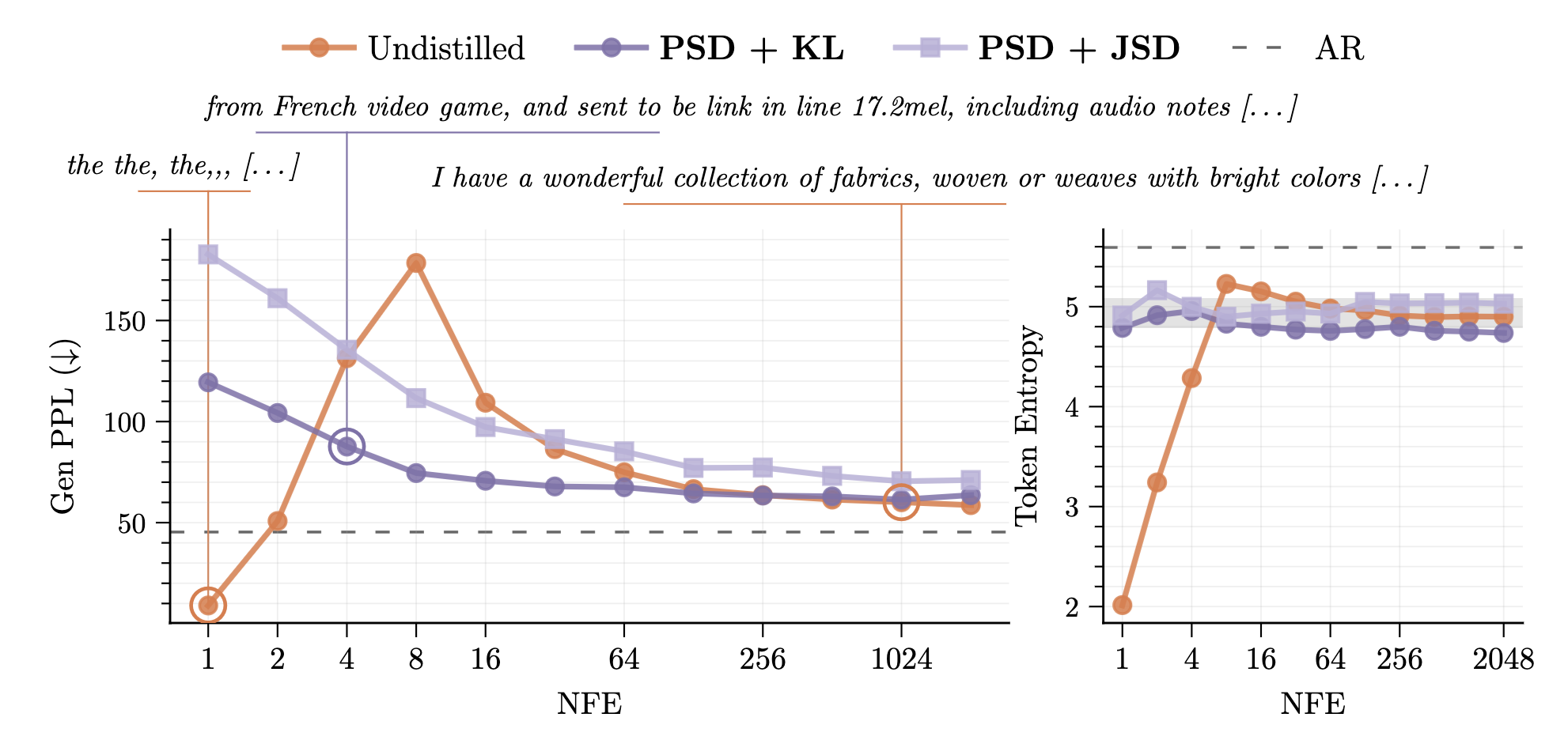
Continuous diffusion and flow matching models could represent a powerful alternative to autoregressive approaches for language modelling (LM), as they unlock a host of advantages currently reserved for continuous modalities, including accelerated sampling and tilting. Recently, several works have demonstrated the possibility of generating discrete data...
AbstractHide abstract
Continuous diffusion and flow matching models could represent a powerful alternative to autoregressive approaches for language modelling (LM), as they unlock a host of advantages currently reserved for continuous modalities, including accelerated sampling and tilting. Recently, several works have demonstrated the possibility of generating discrete data continuously by a simple flow matching process between a Gaussian and the one-hot encoded data distribution. They have further shown the feasibility of accelerated sampling via Categorical Flow Maps (CFMs), resulting in competitive sample quality in the few-step regime. However, this method had only been evaluated at relatively modest scales (<1B), leaving the question of its scalability completely open. In this article, we train a 1.7B-parameter base flow model on 2.1T tokens and self-distill it into a CFM that generates diverse, high-quality text in as few as 4 inference steps while maintaining near-data-level token entropy. Furthermore, we introduce a likelihood bound for CFMs in the semi-discrete setting, and show that they can be used to score the model on standard LM benchmarks, achieving results in the same range as discrete diffusion methods. Finally, we uncover some of the challenges that arise from training these models at scale, and we provide prescriptive insights on loss weighting and time scheduling.
Roos, D.*, Davis, O.*, Eijkelboom, F.*, Bronstein, M., Welling, M., Ceylan, I., Ambrogioni, L., van de Meent, J.W.
We introduce Categorical Flow Maps, a flow-matching method for accelerated few-step generation of categorical data via self-distillation. Building on recent variational formulations of flow matching and the broader trend towards accelerated inference in diffusion and flow-based models, we define a flow map towards the simplex that...
AbstractHide abstract
We introduce Categorical Flow Maps, a flow-matching method for accelerated few-step generation of categorical data via self-distillation. Building on recent variational formulations of flow matching and the broader trend towards accelerated inference in diffusion and flow-based models, we define a flow map towards the simplex that transports probability mass toward a predicted endpoint, yielding a parametrisation that naturally constrains model predictions. Since our trajectories are continuous rather than discrete, Categorical Flow Maps can be trained with existing distillation techniques, as well as a new objective based on endpoint consistency. This continuous formulation also automatically unlocks test-time inference: we can directly reuse existing guidance and reweighting techniques in the categorical setting to steer sampling toward downstream objectives. Empirically, we achieve state-of-the-art few-step results on images, molecular graphs, and text, with strong performance even in single-step generation.
Davis, O., Kessler, S., Petrache, M., Ceylan, İ., Bronstein, M., Bose, J.
Generative modeling over discrete data has recently seen numerous success stories, with applications spanning language modeling, biological sequence design, and graph-structured molecular data. The predominant generative modeling paradigm for discrete data is still autoregressive, with more recent alternatives based on diffusion or flow-matching falling short of...
AbstractHide abstract
Generative modeling over discrete data has recently seen numerous success stories, with applications spanning language modeling, biological sequence design, and graph-structured molecular data. The predominant generative modeling paradigm for discrete data is still autoregressive, with more recent alternatives based on diffusion or flow-matching falling short of their impressive performance in continuous data settings, such as image or video generation. In this work, we introduce Fisher-Flows, a novel flow-matching model for discrete data. Fisher-Flows takes a manifestly geometric perspective by considering categorical distributions over discrete data as points residing on a statistical manifold equipped with its natural Riemannian metric: the Fisher-Rao metric. As a result, we demonstrate that discrete data itself can be continuously reparameterised to points on the positive orthant of the \(d\)-hypersphere \(\mathbb{S}^d_+\), which allows us to define flows that map any source distribution to target in a principled manner by transporting mass along (closed-form) geodesics of \( \mathbb{S}^d_+ \). Furthermore, the learned flows in Fisher-Flows can be further bootstrapped by leveraging Riemannian optimal transport leading to improved training dynamics. We prove that the gradient flow induced by Fisher-Flows is optimal in reducing the forward KL divergence. We evaluate Fisher-Flows on an array of synthetic and diverse real-world benchmarks, including designing DNA Promoter, and DNA Enhancer sequences. Empirically, we find that Fisher-Flows improves over prior diffusion and flow-matching models on these benchmarks.